길벗 출판사의 <코틀린을 다루는 기술> 4장의 내용을 요약한 글입니다.
재귀 함수로 의도를 명확히 표현하기
여러 알고리즘은 재귀 함수로 정의된다. 재귀를 사용하지 않고 알고리즘을 구현하려면 재귀 알고리즘을 비재귀 알고리즘으로 변환해야 하는데, 이 과정에서 알고리즘의 원래의 의도를 놓쳐버리는 실수를 범할 수 있다. 프로그램은 작성하는 것보다 읽는 경우가 더 많으므로 프로그램이 과업을 처리하는 '과정'보다는 어떤 일을 하는지 '의도'를 명확히 보여주는 코드를 작성하는 것이 중요하다.
코드는 단 한번 작성되지만, 여러 번 읽힌다
자바에서 재귀 함수를 사용하는 경우는 거의 없다. 그 이유는 자바 컴파일러가 재귀 함수 처리를 제대로 구현하지 못했기 때문이다. 코틀린의 경우 재귀 함수에 대해 더 나은 구현을 제공하기 때문에 재귀를 제대로 다루고 사용할 수 있다.
공재귀와 재귀
공재귀는 첫 단계부터 계산을 시작하며, 한 단계의 출력을 다음 단계의 입력으로 사용한다. 재귀는 마지막 단계부터 계산을 시작하며, 한 단계의 출력이 그 전 단계의 입력으로 사용된다.
문자(Char)로 이루어진 리스트를 하나로 묶어서 문자열(String)로 만드는 예제를 보며 공재귀와 재귀를 이해해보자.
공재귀 함수의 예
fun toString(list: List<Char>, s: String = ""): String =
if (list.isEmpty())
s
else
toString(list.subList(1, list.size), append(s, list[0]))* fun append(s: String, c: Char): String = "$s$c"
재귀 함수의 예
fun toString(list: List<Char>, s: String = ""): String =
if (list.isEmpty())
s
else
prepend(list[0], toString(list.subList(1, list.size)))* fun prepend(s: String, c: Char): String = "$c$s"
공재귀는 첫 단계부터 append 계산의 결과를 다음 단계의 입력으로 넘겨주는 것을 알 수 있다. 반면, 재귀의 경우 가장 마지막 단계에서 최종조건 list.isEmpty() 를 만족해야만 계산이 시작될 수 있다. 그 전까지의 중간 단계는 메모리 어딘가에 저장해두어야 한다. JVM에서는 이 중간 단계를 스택에 넣어두는데, 크기 제약이 매우 크기 때문에 계산 단계가 많아지면(자바는 약 3,000단계, 코틀린은 20,000단계까지 넣을 수 있음) StackOverflowException 발생의 위험성이 있다. 그렇기 때문에 재귀적 처리과정을 피하고 재귀를 공재귀로 바꾸어 작성해야 한다.
꼬리 호출 제거 사용하기
물론, 재귀도 공재귀만큼은 아니지만 어쨋든 스택 공간을 사용하기 때문에 스택을 고갈시킬 가능성이 있다. 이 문제를 완전히 없애는 방법은 공재귀 함수를 루프로 바꾸어주는 꼬리 호출 제거(TCE, Tail Call Elimination)를 사용하는 것이다.
꼬리 호출(꼬리 재귀 혹은 꼬리 재귀 호출이라고도 함)이란 함수가 재귀 호출의 결과에 다른 연산을 가하지 않고 바로 반환하는 것을 말한다. 예를 들어, fun foo(arg) { ... return foo(arg ) } 는 꼬리 호출이고, fun boo(arg) { ... return arg + boo(arg) } 는 꼬리 호출이 아니다. 꼬리 호출은 호출된 함수를 위한 스택 프레임을 새로 할당할 필요 없이 호출하는 쪽의 기존 스택 공간을 재활용할 수 있다.
위에서 본 문자 리스트를 문자열로 만드는 공재귀 함수의 예제 코드를 루프로 바꾸면 다음과 같다.
fun toString(list: List<Char>): String {
var s = ""
for (c in list) s = append(s, c)
return s
}코틀린에서 꼬리 호출 제거를 사용하는 방법은 간단하다. 함수 선언 앞에 tailrec 키워드를 붙이면 컴파일러가 알아서 TCE를 적용해 공재귀 함수를 루프로 바꿔준다.
tailrec fun toString(list: List<Char>, s: String = ""): String =
if (list.isEmpty())
s
else
toString(list.subList(1, list.size), append(s, list[0]))
재귀를 공재귀로 변환하기
1부터 n까지 정수를 더하는 재귀 함수를 작성하면 다음과 같다.
fun sum(n: Int): Int = if (n < 1) 0 else n + sum(n - 1)재귀가 공재귀보다 메모리 차원에서 덜 효율적이지만, 작성이 훨씬 쉽다는 큰 장점이 있다. 그러나 위 코드에서 sum(n - 1)의 결과를 알기 전에 n을 더할 수 없다. 모든 단계를 스택에 저장하고 마지막 단계의 결과값을 알 때까지 기다려야 한다. 이 함수를 공재귀로 구현하여 TCE를 사용하는 코드로 바꿔보자.
1. 재귀를 루프로 작성한다.
먼저 위 구현에 대응하는 루프를 작성하면 다음과 같다. 코틀린에는 전통적인 for 루프가 없으므로 while 루프를 사용해야한다.
fun sum(n: Int): Int {
var s = 0
var i = 0
while(i <= n) {
s += i
i++
}
return s
}루프를 사용하면 잘못될 여지가 많다. 흔히 조건을 <= 가 아닌 < 로 쓴다거나, i 를 먼저 증가시킨 후 s 를 증가시키는 등의 실수로 인해 문제가 발생한다.
2. 루프의 변수를 함수 파라미터로 추가한다.
루프의 변수를 파라미터로 가지는 도우미 함수 sum(n, s, i) 를 작성하고, 주 함수 sum(n) 가 도우미 함수를 호출하도록 해보자.
sum(n: Int, s: Int, i: Int): Int = ...sum(n: Int): Int = sum(n, 0, n)
3. 도우미 함수를 주 함수의 로컬 함수로 포함시킨다.
계산 과정에서 도우미 함수의 첫 번째 파라미터 n의 값은 바뀌지 않는다. 도우미 함수를 주 함수의 로컬 함수로 포함시키면 파라미터 n에 대해 닫혀있게 만들어서 파라미터를 하나 줄일 수 있다.
fun sum(n: Int): Int {
fun sum(s: Int, i: Int): Int = ...
return sum(0, n)
}내부 도우미 함수의 이름을 정하는 몇 가지 관례가 있다. 어떤 방식을 선택하든 항상 일관성을 지켜 작성하면 된다.
- go 또는 process 같은 이름으로 통일한다.
- sum_ 처럼 주 함수 이름 뒤에 밑줄을 붙인다.
- 주 함수와 도우미 함수의 시그니처가 다르면 주 함수와 똑같은 이름을 붙인다.
4. 도우미 함수를 구현한다.
루프 버전을 생각해보면, 한 이터레이션마다 s 와 i 가 각각 s + i 와 i + 1 로 변경된다. 도우미 함수도 마찬가지로 자기 자신을 호출하면서 이렇게 변경된 값을 넘기면 된다.
fun sum(s: Int, i: Int): Int = sum(s + i, i + 1)위 함수는 절대 끝나지 않기 때문에 종료 조건을 작성하여 결과 값을 반환하도록 한다.
fun sum(n: Int): Int {
fun sum(s: Int, i: Int): Int = if (i >= n) s else sum(s + i, i + 1)
return sum(0, n)
}
5. TCE를 적용한다.
마지막으로 컴파일러에게 TCE를 적용한다고 알려 꼬리 호출을 제거한다.
fun sum(n: Int): Int {
tailrec fun sum(s: Int, i: Int): Int =
if (i >= n) s else sum(s + i, i + 1)
return sum(0, n)
}
리스트에서 재귀 함수 사용하기
foldLeft 함수
리스트에 대한 재귀 함수는 주로 리스트의 첫 번째 원소와 나머지 원소들에 같은 처리를 적용한 결과를 조합하는 방법으로 이루어진다. 이때 루프를 사용하지 않고 프로그래밍하기 위해 사용하는 함수가 foldLeft 함수이다. foldLeft 함수는 StackOverflow 발생에 대한 걱정 없이 공재귀를 사용할 수 있게 해준다.
예제를 통해 foldLeft 함수를 이해해보자. 다음 코드는 정수 리스트에 들어 있는 모든 원소의 합을 구하는 함수를 작성한 것이다.
fun sum(list: List<Int>): Int =
if (list.isEmpty())
0
else
list.first() + sum(list.drop(1))이 함수는 꼬리 재귀가 아니므로 원소가 몇천 개 이상일 때는 사용할 수 없다. 꼬리 재귀로 바꾸어보자.
fun sum(list: List<Int>): Int = {
tailrec fun sum(list: List<Int>, acc: Int): Int =
if (list.isEmpty())
acc
else
sum(list.drop(1), acc + list.first())
return sum(list, 0)
}
이번에는 모든 타입의 리스트에 대해 각 원소 사이를 구분 문자열로 분리해 나열한 문자열을 만드는 함수를 살펴보자.
fun <T> makeString(list: List<T>, delim: String): String =
when {
list.isEmpty() ->
""
list.drop(1).isEmpty() ->
"${list.first()}${makeString(list.drop(1), delim)}"
else ->
"${list.first()}$delim${makeString(list.drop(1), delim)}"
}이 함수도 마찬가지로 꼬리 재귀로 바꾸어보자.
fun <T> makeString(list: List<T>, delim: String): String {
tailrec fun makeString(list: List<T>, acc: String): String =
when {
list.isEmpty() ->
acc
acc.isEmpty() ->
makeString(list.drop(1), "${list.first()}")
else ->
makeString(list.drop(1), "$acc$delim${list.first()}")
}
return makeString(list, "")
}
sum 과 makeString 두 함수에 대한 공통점이 보이는가? 두 함수 모두 첫 번째 원소에 대해 '어떤 연산'을 수행하고, 동일한 연산을 나머지 원소들에 대해서도 차례로 적용해나간다. 이러한 공통 부분을 추상화하여 foldLeft 라는 제네릭 함수를 만들 수 있다.
fun <T, U> foldLeft(list: List<T>, z: U, f: (U, T) -> U): U {
tailrec fun foldLeft(list: List<T>, acc: U): U =
if (list.isEmpty())
acc
else
foldLeft(list.drop(1), f(acc, list.first()))
return foldLeft(list, z)
}foldLeft 함수는 T 타입을 원소로 갖는 리스트와 연산의 결과를 담을 U 타입의 변수, 그리고 (U, T) 에서 U 로 가는 함수를 파라미터로 가지며 결과로 U 타입을 반환한다.
이렇게 만든 foldLeft 함수를 적용하여 sum 과 makeString 함수를 다시 작성하면 다음과 같다.
fun sum(list: List<Int>): Int = foldList(list, 0, Int::plus)fun <T> makeString(list: List<T>, delim: String): String =
foldLeft(list, "") { s, t -> if (s.isEmpty()) "$t" else "$s$delim$t" }코틀린에서는 마지막 인자가 함수일 때, 함수 값을 괄호 밖으로 빼서 쓰는 방식을 선호한다.
foldRight 함수
foldRight 함수는 foldLeft 함수와 마찬가지로 루프를 사용하지 않고 재귀적인 구현을 위해 사용하는 함수다. 차이점은 공재귀 대신 재귀를 사용하여 리스트의 원소를 반대 방향으로 접근한다는 것이다.
문자 리스트를 문자열로 만드는 예제를 살펴보자.
fun toString(list: List<Char>): String =
if (list.isEmpty())
""
else
prepend(list.first(), toString(list.drop(1)))여기서도 마찬가지로 동일 연산을 모든 리스트에 적용할 수 있도록 추상화 할 수 있다.
fun <T, U> foldRight(list: List<T>, identity: U, f: (T, U) -> U): U =
if (list.isEmpty())
identity
else
f(list.first(), foldRight(list.drop(1), identity, f))foldRight 함수는 T 타입의 원소를 가지는 리스트와 초기값을 나타내는 U 타입의 identity 변수, 그리고 (T, U) 에서 U 로 가는 함수를 파라미터로 가진다. 이렇게 만들어진 foldRight 함수를 사용하여 toString 함수를 다시 작성해보자.
fun toString(list: List<Char>): String =
foldRight(list, "", { c, s -> prepend(c, s) })
여기까지 foldLeft 와 foldRight 함수의 원리를 살펴보았다. 코틀린에서 List 클래스에 접기 연산을 사용할 때는 두 함수를 직접 작성할 필요 없이 코틀린에서 제공하는 fold 와 foldRight 함수를 사용하면 된다. 단, foldRight 함수는 리스트가 길어지면 StackOverflow를 발생시킬 수 있기 때문에 가능하면 fold 를 우선적으로 사용해야 한다.
리스트 뒤집기
프로그래밍을 하다보면, 리스트를 뒤집어야 하는 경우가 발생한다. 코틀린에는 이미 List 클래스에 reversed 라는 함수가 들어있으므로 이를 사용하면 된다. 리스트 접기 연산의 이해를 높히기 위해 foldLeft 함수를 사용하여 reverse 함수를 직접 작성해보자.
리스트를 뒤집기 위해 각 단계마다 이전 단계의 결과 리스트 맨 앞에 첫 번째 원소를 이어 붙이면 된다.
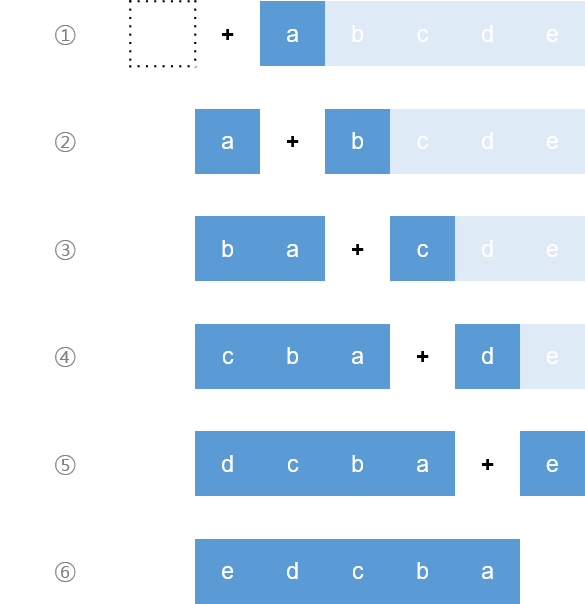
이해를 돕기 위해 그림으로 연산 단계를 표현해보았다. 여기서 주의할점은 + 연산의 결과인데, [a] + [b] 의 결과가 [a, b] 가 아닌 [b, a] 가 된다는 것이다. 이를 코드로 표현하기 위해서는 리스트의 맨 앞에 원소를 추가하는 함수를 구현해야 한다.
fun <T> prepend(list: List<T>, elem: T): List<T> = listOf(elem) + list코틀린의 + 연산자는 리스트의 맨 뒤에 원소를 추가하거나 리스트끼리 연결할 때 사용할 수 있다. 리스트의 맨 앞에 원소를 추가하기 위해서 앞에 붙일 원소를 단일 리스트로 만들어주었다.이제 리스트를 왼쪽으로 접으며 위에 정의한 prepend 함수를 적용해 리스트를 뒤집을 수 있다.
fun <T> reverse(list: List<T>): List<T> = foldLeft(list, listOf(), ::prepend)간단하게 구현했지만, prepend 함수에서 단일 원소 리스트를 만든 것은 어떻게 보면 약간의 눈속임이다. 그렇다면 단일 원소 리스트를 만들지 않고 prepend 를 정의하려면 어떻게 해야될까?
foldLeft 를 사용해 리스트를 복사하는 연산을 응용하여 prepend 함수를 구현할 수 있다.
fun <T> prepend(list: List<T>, elem: T): List<T> =
foldLeft(list, listOf(elem)) { lst, elem -> lst + elem }리스트를 복사하는데, elem 을 첫 번째 원소로 맨 앞에 붙여주면 간단하게 해결된다.
이렇게 구현한 prepend 나 reverse 는 리스트를 여러 번 순회하기 때문에 실제 프로그램에서 사용하면 매우 비효율적이다. 코틀린 List 를 사용하는 경우 List 에 정의된 reversed 함수를 사용하자.
공재귀 리스트
공재귀 리스트는 0(포함) 부터 limit(미포함) 까지의 정수 리스트다. 첫 번째 원소(i = 0)에서 시작하여 함수(i -> i++) 를 적용하는 것을 i = limit - 1 까지 반복하며 리스트를 생성하는 range 함수를 작성해보자.
fun range(start: Int, end: Int): List<Int> {
val result: MutableList<Int> = mutableListOf()
var index = start
while (index < end) {
result.add(index)
index++
}
return result
}이 함수를 파라미터화 하여 임의의 타입과 조건에 대해 작동하는 unfold 함수를 작성해보자.
fun <T> unfold(seed: T, f: (T) -> T, p: (T) -> Boolean): List<T> {
val result: MutableList<T> = mutableListOf()
val elem = seed
while (p(elem)) {
result.add(elem)
elem = f(elem)
}
return result
}이제 unfold 함수를 사용하여 range 함수를 구현하자.
fun range(start: Int, end: Int): List<Int> = unfold(start, { it + 1 }, { it < end })
range 의 재귀 버전을 작성하면 어떻게 될까?
fun range(start: Int, end: Int): List<Int> =
if (end <= start)
listOf()
else
prepend(range(start + 1, end), start)마찬가지로, range 를 파라미터화 하여 unfold 함수의 재귀 버전을 작성해보자.
fun <T> unfold(seed: T, f: (T) -> T, p: (T) -> Boolean): List<T> =
if (p(seed))
prepend(unfold(f(seed), f, p), seed)
else
listOf()
unfold 함수의 꼬리 재귀 버전을 만들 수 있을까?
fun <T> unfold(seed: T, f: (T) -> T, p: (T) -> Boolean): List<T> {
tailrec fun unfold_(acc: List<T>, seed: T): List<T> =
if (p(seed))
unfold_(acc + seed, f(seed))
else
acc
return unfold_(listOf(), seed)
}
메모화
메모화(memoization)는 말 그대로 한번 계산된 결과를 어딘가에 메모해두고 나중에 같은 계산을 다시 수행하지 않고 결과를 바로 반환하는 기법이다. 메모화를 사용하면 O(n) 시간이 걸리는 연산을 O(1) 시간에 수행할 수 있다는 장점이 있다.
피보나치 수열을 생각해보자. f(n) 을 출력하고 싶을 때, f(1) f(2) ... f(n) 까지의 모든 수열을 계산해야 한다. 게다가 f(n) 을 계산하려면 f(1) f(2) ... f(n-1) 값이 필요하다. 즉, 이전 값을 모두 다시 계산해야 하는 것이다.
이미 계산 된 결과를 어딘가에 저장해둔다면 이전 값을 모두 재귀적으로 계산하지 않아도 될 것이다.
루프에서 메모화 사용하기
0 부터 n 까지 피보나치 수열을 콤마로 구분해서 나열한 문자열을 반환하는 fibo 함수를 루프를 사용해서 작성하면 다음과 같다. 루프 내에서 다음 단계로 가기 전에 f(n) 과 f(n-1) 값을 각각 변수 fibo1 과 fibo2 에 저장한다. 이 두 변수가 메모화를 담당하는 변수다.
fun fibo(limit: Int): String =
when {
limit < 1 -> throw IllegalArgumentException()
limit == 1 -> "1"
else -> {
var fibo1 = BigInteger.ONE
var fibo2 = BigInteger.ONE
var finonacci: BigInteger
val builder = StringBuilder("1, 1")
for (i in 2 until limit) {
fibonacci = fibo1.add(fibo2)
builder.append(", $fibonacci")
fibo1 = fibo2
fibo2 = fibonacci
}
builder.toString()
}
}
재귀 함수에서 메모화 사용하기
다음은 fibo 함수를 재귀적 기법으로 작성한 것이다. 마찬가지로 도우미 함수의 파라미터로 f(n) 과 f(n-1) 에 해당하는 값을 넘겨준다. (앞에서 루프를 재귀함수로 변환할 때 루프에 사용한 변수를 함수의 파라미터로 변환하는 것을 배웠다.)
fun fibo(number: Int): String {
tailrec fun fibo(acc: List<BigInteger>,
acc1: BigInteger,
acc2: BigInteger,
x: BigInteger): List<BigInteger> =
when (x) {
BigInteger.ZERO -> acc
BigInteger.ONE -> acc + (acc1 + acc2)
else -> fibo(acc + (acc1 + acc2), acc2, acc1 + acc2, x - BigInteger.ONE)
}
val list = fibo(listOf(),
BigInteger.ONE,
BigInteger.ZERO,
BigInteger.valueOf(number.toLong()))
return list.joinToString(", ")
}
자동 메모화 사용하기
'Kotlin > 코틀린을 다루는 기술' 카테고리의 다른 글
| 7장. 오류와 예외 처리하기 (0) | 2020.07.31 |
|---|---|
| 6장. 선택적 데이터 처리하기 (0) | 2020.07.23 |
| 3장. 함수로 프로그래밍하기 (0) | 2020.07.14 |
| 1장. 프로그램을 더 안전하게 만들기 (0) | 2020.07.04 |

댓글