길벗 출판사의 <코틀린을 다루는 기술> 1장의 내용을 요약한 글입니다.
[지은이의 말]
코틀린(Kotlin)
1. JVM(Java Virtual Machine) 기반의 언어다.
코틀린은 JVM(Java Virtual Machine) 기반의 언어로 코틀린으로 작성한 소스코드 파일(.kt)을 컴파일하면 자바 클래스 파일(.class)이 생성되며, 자바와 동일하게 플랫폼 독립적이다. 즉, 거의 모든 플랫폼(JVM이 돌아가는 환경이라면 어디든)에서 실행이 가능하다.
2. Java 와의 호환성이 높다.
다른 JVM 기반의 언어들(스칼라, 그루비, 클로저 등)은 자바와 라이브러리 수준에서 통합된다. '라이브러리 수준에서 통합된다'라는 말은 스칼라 프로그램에서 자바로 작성된 라이브러리를 사용할 수 있고, 반대로 자바 프로그램에서 스칼라로 작성된 라이브러리를 사용할 수 있다는 뜻이다. 그러나 이 둘의 언어를 하나의 프로젝트(또는 모듈)에서 함께 사용하여 빌드하는 것은 불가능하며, 각각 별도의 모듈로 빌드해야 한다.
반면, 코틀린의 경우는 자바와 프로젝트 수준에서 통합된다. 한 프로젝트 내에서 자바와 코틀린을 혼합해서 사용하고 같은 모듈로 빌드해도 아무 문제가 없을 정도로 호환성이 높다.
3. 함수형 프로그래밍 기법에 친화적이다.
코틀린은 불변성, 참조 투명성, 치환 모델, 제어 구조 회피, 지연 계산 등 함수형 프로그래밍이 가능하도록 하는 여러 기법들을 제공한다. 각각의 기법에 대한 세부적인 내용은 뒤에서 차차 자세히 다룰 것이다.
4. 더 안전한 프로그램 작성에 용이하다.
프로그램에서 자주 발생하는 대표적인 버그로 널(null) 참조를 들 수 있다. 코틀린에서는 널이 될 수 있는 타입과 될 수 없는 타입을 나누어 놓았기 때문에 널 참조로 인해 발생하는 버그를 예방할 수 있다.
그 외에도 멀티스레드 환경에서의 상태 공유로 인한 버그, 제어 구문이나 루프로 인하여 생기는 버그, 외부 세계(DB나 네트워크 통신 등의 외부 요소)에 의존하는 부분에서 발생할 수 있는 버그 등 프로그래밍을 하면서 흔히 발생하는 이슈들을 코틀린을 사용하면 더 효율적으로 다룰 수 있기 때문에 더욱 안전한 프로그램을 작성할 수 있다.
[1장. 프로그램을 더 안전하게 만들기]
프로그래밍의 함정
프로그램에서 발생하는 버그에는 눈에 띄는 분명한 버그와 눈에 띄지 않는 불분명한 버그가 있다. 눈에 띄는 버그는 비교적 초기에 발견 즉시 해결할 수 있기 때문에 덜 치명적이다. 불분명한 버그는 언제 자신의 모습을 드러낼지 몰라 더 위험하다. 오늘까지 잘 실행되던 프로그램이 내일 갑자기 죽을수도 있다는 것이다.
SDLC(Software Development Life Cycle)에서 버그가 발견되는 시점이 후반부로 갈수록 비용이 점점 더 많이 든다. 아무리 잘 작성된 프로그램이라 할지라도 버그가 없는 프로그램은 없다. 비용을 최소화하여 안전한 프로그램을 만들려면 이왕이면 초반부에 버그를 발견하기 위한 Shift-Left 전략이 필요하다. 그러기 위해서는 버그가 어디 숨어있을지 모르는 복잡한 프로그램을 작성하기 보다는, 버그가 없음이 명확히 보이는 단순한 프로그램을 작성하려는 훈련이 잘 되어 있어야한다.
Systems development life cycle - Wikipedia
Systems engineering term Model of the systems development life cycle, highlighting the maintenance phase In systems engineering, information systems and software engineering, the systems development life cycle (SDLC), also referred to as the application de
en.wikipedia.org
결정적인 프로그램 작성하기
프로그램이 결정적(deterministic)이라는 것은 프로그램의 결과를 예측하고 추론할 수 있다는 뜻이다. 결정적인 프로그램은 같은 입력이 주어지면 항상 같은 결과를 내놓으며, 외부 요소에 의해 결과가 달라지지 않는다.
아주 간단한 예로 두 정수 a, b 값을 인자로 받아서 a + b 값을 반환하는 함수를 살펴보자.
fun add(a: Int, b: Int): Int = a + b위 함수는 오직 인자에 따라서만 결과 값이 결정된다. 같은 입력이 주어지면 항상 같은 결과가 나오기 때문에 프로그램의 동작을 항상 예측할 수 있다.
만약 a + b 값을 반환하기 전에 그 결과를 파일에 쓰도록 바꾼다면, 그 프로그램은 동작을 예측할 수 없게 된다.
fun add(a: Int, b: Int): Int {
writeToFile(a + b)
return a + b
}결과값을 쓰려는 파일이 접근할 수 없는 파일이거나, 저장하는 과정에 문제가 생기는 등 외부 요소들에 의해 프로그래머가 예측할 수 없는 예외 상황들이 발생할 가능성이 있다. 이 프로그램은 같은 입력이 주어지더라도 결과를 예측할 수 없는 비결정적(nondeterministic)인 프로그램이다.
외부 세계의 상태를 변경하지도 않고 외부 상태에 의존하지도 않는 프로그램 (또는 함수)를 참조 투명(referentially transparent)한 프로그램 (또는 함수)라고 한다. 참조 투명한 함수만을 사용하는 프로그램은 결정적이며, 예측 가능하고, 안전하다. 참조 투명성은 결정적인 프로그램을 작성할 수 있게 도와주는 기법이라고 할 수 있다.
-
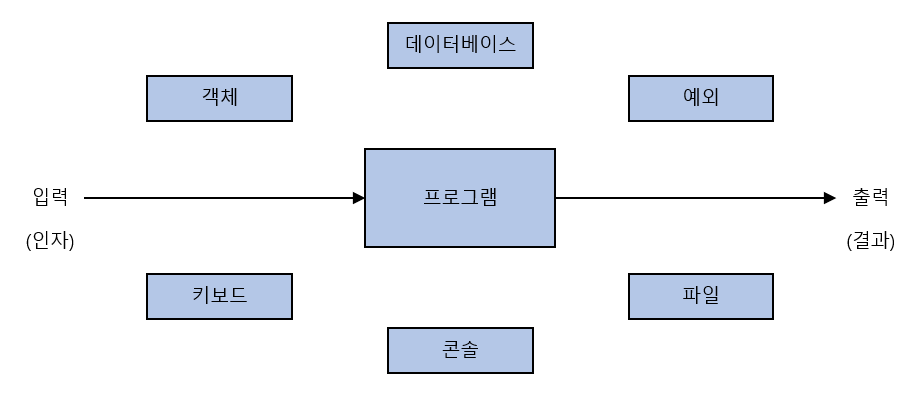
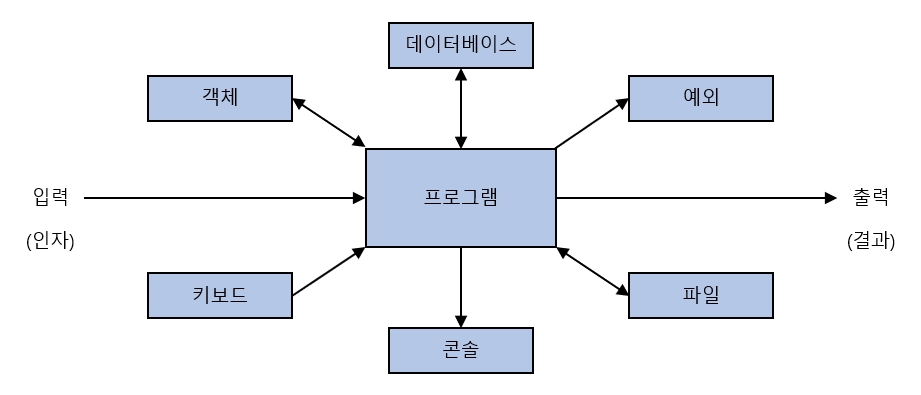
참조 투명한 프로그램과 참조 투명하지 않은 프로그램의 차이점
| 참조 투명한 프로그램 |
참조 투명하지 않은 프로그램 |
 |
 |
|
입력을 받아 결과를 반환하는 행위를 제외하고는 외부 세계와 상호 작용하지 않는다. 결과값은 오직 입력에만 영향을 받는다. |
외부로부터 데이터를 읽거나 외부 객체를 변경하거나 파일에 로그를 남기거나 키보드 입력을 받는 등 외부 세계와 상호 작용을 한다. 그 결과는 외부 세계의 영향을 받기 때문에 예측 불가능하다. |
안전하게 부수 효과 처리하기
외부 세계와의 모든 상호 작용을 효과(effect)라고 한다. 어떤 프로그램이든 어느정도 외부 세계에 의존하기 마련이다. 프로그램의 일부 영역 안에서만 효과가 일어나도록 제한한다면 더욱 안전한 프로그램이 될 수 있다. 다시 말해, 인자를 받아서 값을 반환하는 함수는 외부 객체의 상태를 변경하는 부수 효과(side effect) 없이 값만 반환해야 하며, 효과를 처리하는 부분은 따로 분리시키거나 최대한 추상화해야 한다.
신용 카드로 도넛을 구매하는 간단한 코드를 살펴보자.
fun buyDonut(creditCard: CreditCard): Donut {
val donut = Donut()
creditCard.charge(Donut.price) // 신용 카드 청구 (부수 효과)
return donut
}buyDonut에 신용 카드를 인자로 넘기면 도넛의 금액 만큼 카드를 청구하고, 구매한 도넛을 반환해준다.
중간에 호출되는 charge 함수는 은행 서버에 연결해 해당 신용 카드의 유효성을 검사하고 승인을 받은 후 거래 정보를 등록하는 과정을 거칠 것이다. 이는 외부 세계의 데이터를 읽고 변경하는 일종의 부수 효과다.
이 코드를 테스트하려면
-
은행에 목(Mock) 계정으로 거래 정보를 등록하거나
-
목 신용카드를 만들어 charge 함수를 호출할 때 일어나는 효과를 등록해야 한다.
위 코드에서 부수 효과를 없애면 목을 사용하지 않고 테스트하는 것이 가능해진다. 함수 내부에서 카드를 청구하는 것이 아니라, 카드 지급을 나타내는 표현을 반환 값에 덧붙이면 부수 효과를 없앨 수 있다.
카드 지급을 표현하기 위해 Payment 와 Purchase 두 개의 클래스를 정의하였다. Payment 에는 신용 카드 정보와 지급 금액, Purchase 에는 구매한 Donut 과 Payment 정보를 담는다.
class Payment(val creditCard: CreditCard, val amount: Int)class Purchase(val donut: Donut, val payment: Payment)두 클래스를 사용하여 buyDonut 함수에서 신용 카드를 직접 청구하지 않고, 카드 지급 정보만을 반환하도록 변경하였다.
fun buyDonut(creditCard: CreditCard): Donut {
val donut = Donut()
val payment = Payment(creditCard, Donut.price)
return Purchase(donut, payment)
}이제 buyDonut 은 부수 효과가 없는 참조 투명한 함수이며, 목을 사용하지 않고도 프로그램을 테스트 할 수 있다.
또한, 프로그램의 동작을 더 자유롭게 작성할 수 있게 되었다. 신용 카드 지급을 즉시 처리할 수도 있고, 나중에 처리하기 위해 저장해 둘 수도 있으며 같은 카드에 대한 여러 지급을 모아두었다가 한꺼번에 처리할 수도 있다.
다음 코드는 buyDonut 을 테스트하는 코드이다.
class DonutTest {
@Test
fun testBuyDonut() {
val creditCard = CreditCard()
val purchase = buyDonut(creditCard)
assertEquals(Donut.price, purchase.payment.amount)
assertEquals(creditCard, purchase.payment.creditCard)
}
}같은 신용 카드에 대한 여러 지급을 하나로 묶는 코드는 다음과 같이 작성할 수 있다.
class Payment(val creditCard: CreditCard, val amount: Int) {
/**
* 같은 카드에 대한 여러 지급을 하나로 묶는다.
*/
fun combine(payment: Payment): Payment =
if(this.creditCard == payment.creditCard)
Payment(creditCard, this.amount + payment.amount)
else
throw IllegalStateException("Cards don't match.")
companion object {
/**
* 여러 지급을 같은 카드끼리 그룹화한다.
*/
fun groupByCard(payments: List<Payment>): List<Payment> =
payments.groupBy { it.creditCard } // List<Payment>를 신용 카드 기준으로 묶어 Map<CreditCard, List<Payment>>으로 변환
.values // 맵에서 값(value)들만 꺼내 List<List<Payment>> 로 변환
.map { it.reduce(Payment::combine) } // 각 List<Payment>를 combine 함수를 통해 단일 Payment로 축약
}
}combine 함수는 자신의 카드 정보와 인자로 넘어온 payment 의 카드 정보가 일치할 두 지급 금액을 합친 새로운 Payment 객체를 만들어 반환한다. 카드 정보가 일치하지 않을 경우 예외를 던진다.
groupByCard 함수는 여러 지급 정보가 들어있는 List<Payment>를 인자로 받아, 코틀린이 제공하는 List 의 함수들을 적절히 조합하여 같은 카드끼리 지급 정보를 합친 새로운 List<Payment>를 반환한다.
끝까지 추상화하기
앞의 예제 코드에서 쓴 reduce 함수는 추상화의 예를 잘 보여준다. reduce 는 리스트를 축약할 때 사용할 '어떤 연산'을 받아 리스트를 하나의 값으로 축약하는 함수다. 이때, 연산은 같은 타입의 인자 두 개를 받아서 같은 타입의 값을 반환하는 연산(f: (A, A) -> A)이라면 어떤 것이든 reduce 에 사용할 수 있다. 두 원소의 합을 반환하는 연산 sum을 reduce에 사용하면 List에 들어있는 모든 원소의 합을 구할 수 있고, 같은 방법으로 두 원소의 곱을 반환하는 연산을 이용하여 모든 원소의 곱을 구할 수 있다. 두 원소 중 작은 값 또는 큰 값을 반환하는 연산을 사용하여 최솟값 또는 최댓값을 구할 수도 있다. 모든 계산에 공통으로 들어있는 부분을 reduce 에서 수행하고, 필요에 따라 달라지는 부분을 인자로 전달하도록 추상화한 것이다.
마찬가지로 groupByCard 함수도 신용 카드 지급을 카드별로 그룹화할 때만 쓸 수 있는 함수처럼 보이지만, 이 함수를 잘 추상화하면 리스트의 종류와 관계 없이 원소의 특성에 따라 그룹을 지을 수 있다. 추상화된 부분은 한 번만 작성하여 완전히 테스트하면 같은 코드를 다시 구현하면서 생기는 버그를 막을 수 있다. 그 결과 프로그램은 더욱 안전해지고, 재사용성이 좋아지며 유지 보수 또한 쉬워진다.
'Kotlin > 코틀린을 다루는 기술' 카테고리의 다른 글
| 7장. 오류와 예외 처리하기 (0) | 2020.07.31 |
|---|---|
| 6장. 선택적 데이터 처리하기 (0) | 2020.07.23 |
| 4장. 재귀, 공재귀, 메모화 (0) | 2020.07.18 |
| 3장. 함수로 프로그래밍하기 (0) | 2020.07.14 |

댓글